
MySQL is a highly reputable technology serving the modern big data ecosystem. At present, it caters to diversified groups of industries that are involved with enterprise data and IT. MySQL is a relational database management system (RDBMS) developed by Oracle and is based on structure query language (SQL).
Challenges with horizontal scalability
When the size of the data increases, more CPU, memory and IO is needed for your queries to run. The performance of the queries decrease exponentially. In order for your queries to execute quickly, usually one has to add more hardware resources to pump up the database. Unlike application servers, the databases cannot be truly scaled horizontally.
MySQL provides upto 5 read replicas, which helps you scale MySQL horizontally. Which means there’s one write instance and upto 5 read replicas. In order to implement this, the application has to be aware of which instance to hit.
For e.g. we have 1 write instance called MyServerWrite, and 5 read replicas called MyServerRead1, MyServerRead2, MyServerRead3, MyServerRead4 and MyServerRead5. This means all the 6 instances will have different endpoints. So from the application side, the application needs to be aware which endpoint to hit.
This means the application server will have to load balance on it’s own. The following are the limitations
- Identify the type of query, if it’s a write query direct it to MyServerWrite instance
- If the query is read operation, redirect to any of the 5 read replicas
- The application can hit the read replicas in a round robin fashion. The first query goes to MyServerRead1, the second to MyServerRead2 and so on.
AWS Aurora MySQL is an extension to what MySQL Community edition offers, but it still lacks true horizontal scalability. Aurora RDS, provides upto 15 read replicas, it’s own set of limitations. A good thing about Aurora RDS is that, for the read replicas, we can define one single custom endpoint, so MyServerRead1, MyServerRead2 ….. MyServerRead15 can have a custom endpoint myendpont.xxxxxxx.com. Aurora RDS will internally choose which read replica to point to. Another advantage is the ability to auto scale in terms of read replicas. So one can choose upto 15 read replicas in the auto scaling option.
As far as limitations are concerned, with Aurora MySQL, the application has to be aware of read and write queries and direct it accordingly, else if a write operation is directed to the read instance else the query will fail.
To conclude, this is not the type of true horizontal scaling as available with NoSQL databases.
Vitess.io
Vitess.io is the solution to horizontal scaling of MySQL databases. This was originally built to implement database clustering of MySQL instances which is used by youtube. It provides additional benefits like Scalability, performance, connection pooling, shard management etc.
Horizontal scaling through Vitess framework can be achieved in the following way
- Localling installing the vitess framework
- Using kubernates
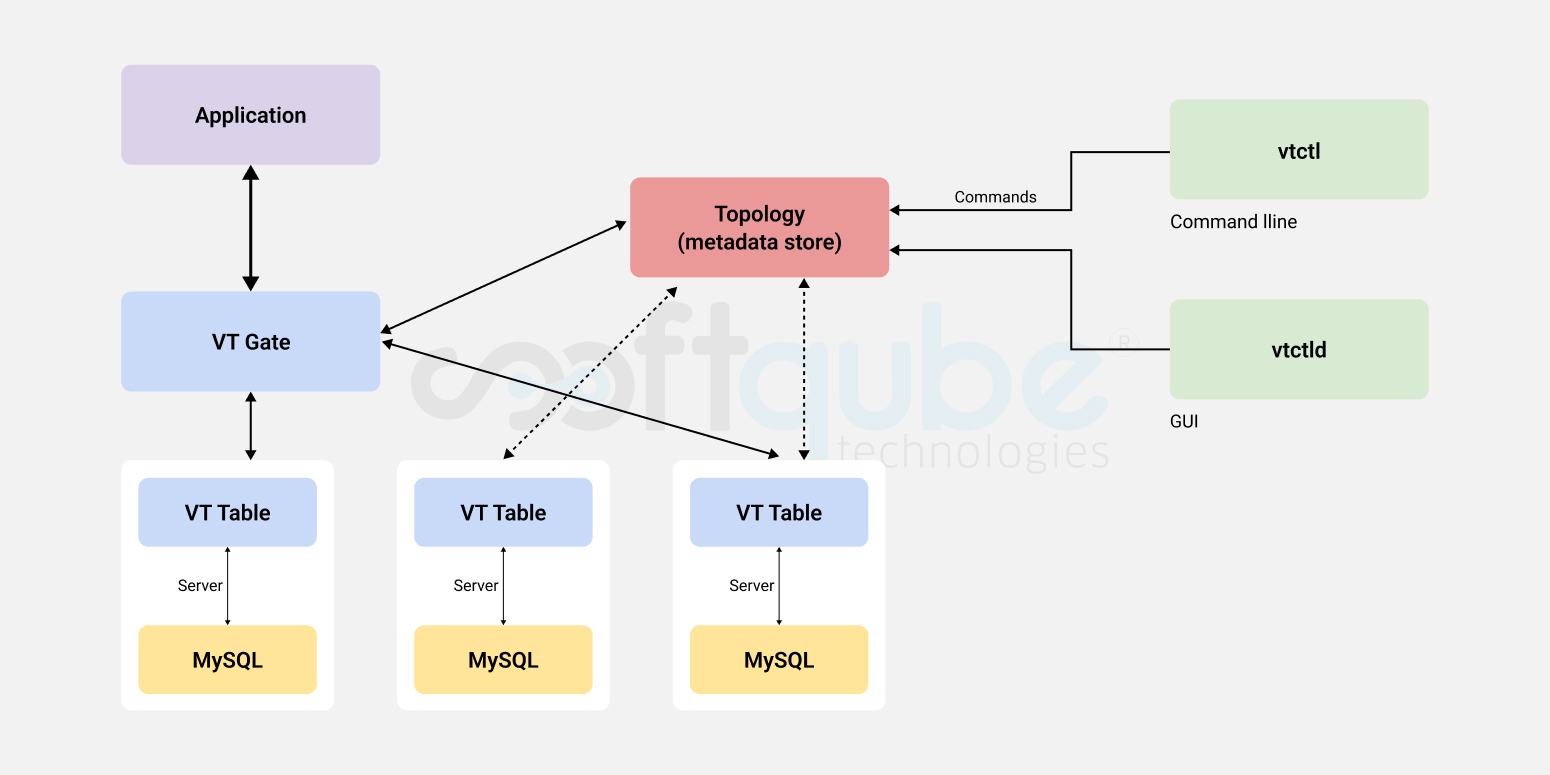
PlanetScale.com provides managed MySQL instances built on the vitess framework on Database as a service model(DaaS). It has amazing features, where you can deploy database changes as a code and is fully DevOps compatible. They have a CLI which can make things faster. With data sharding, we don’t need to worry about growing database size.
Conclusion
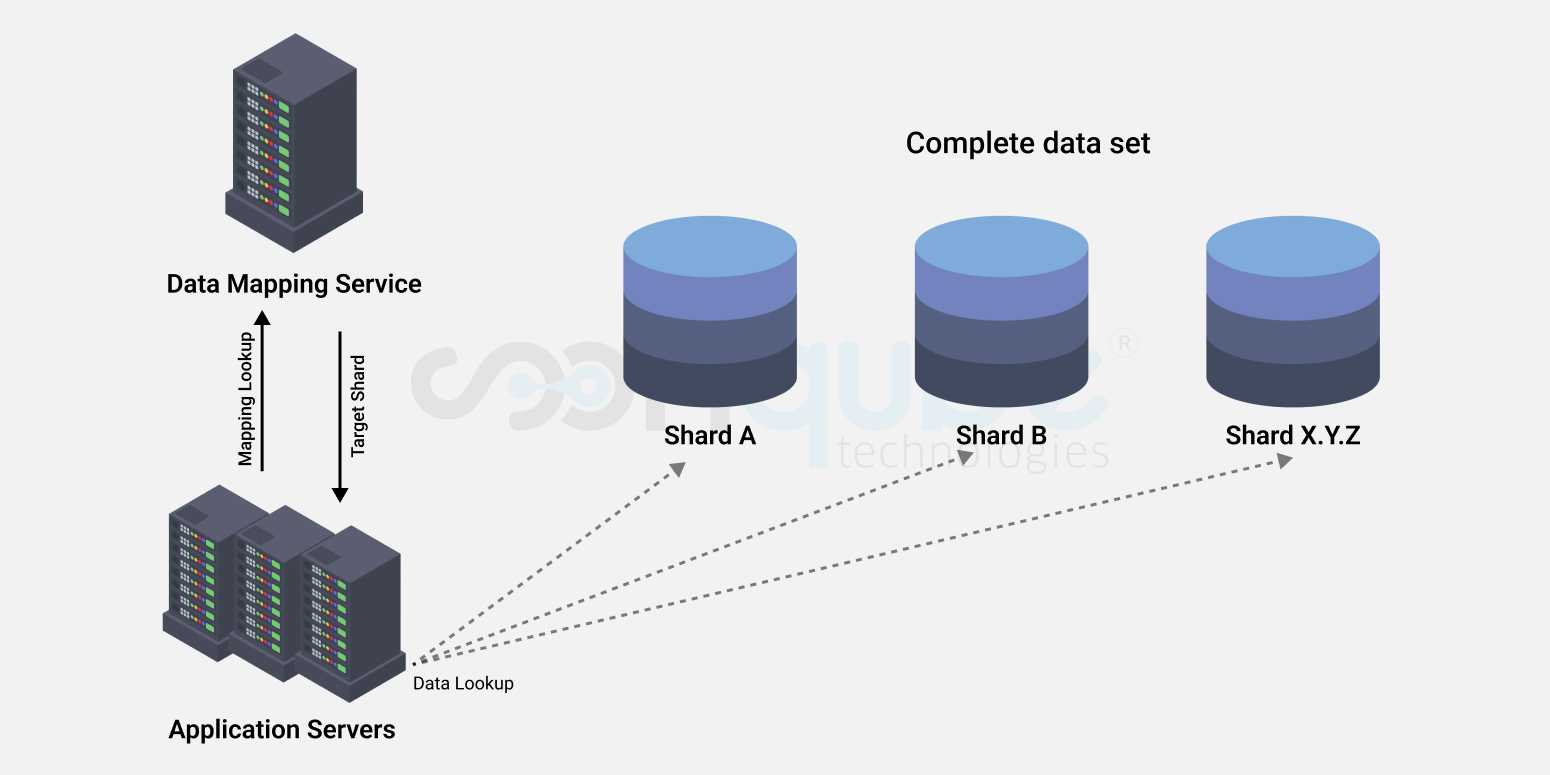
Although MySQL and Amazon Aurora RDS have read replicas which “sort” of serves the purpose of horizontal scaling, it’s not a true horizontal scaling solution. Vitess framework on the other hand solves the purpose.
